Ottimizzazione delle performance di modelli transformer su hardware edge
Ottimizzazione delle performance di modelli transformer su hardware edge: tecniche avanzate per sistemi a bassa potenza
Introduzione
Viviamo in un’era in cui l’Intelligenza Artificiale (AI) si sta radicando profondamente in diversi aspetti della nostra vita quotidiana. Dagli assistenti vocali intelligenti alle automobili a guida autonoma, i modelli basati su reti neurali stanno trasformando il modo in cui interagiamo con il mondo digitale. Un aspetto chiave di questa rivoluzione è la necessità di eseguire tali modelli in modo efficace su dispositivi a bassa potenza, come smartphone e dispositivi IoT. L’ottimizzazione transformer edge diventa così cruciale, consentendo a questi modelli di funzionare in modo efficiente anche su hardware limitato.
In questo articolo, esploreremo come le tecniche di pruning, quantizzazione e distillazione possano migliorare le prestazioni dei modelli transformer su dispositivi edge. Discuteremo inoltre il perché queste tecniche sono essenziali, come funzionano, le loro applicazioni pratiche e le sfide che comportano. Per coloro che sono curiosi di tecnologia e desiderano comprendere meglio il futuro dell’AI su dispositivi edge, questo articolo fornirà una guida dettagliata e accessibile.
Cos’è ottimizzazione transformer edge e perché è importante
I modelli transformer hanno rivoluzionato il campo dell’AI, in particolare nel dominio del linguaggio naturale, grazie alla loro capacità di gestire relazioni di lungo raggio all’interno dei dati. Tuttavia, questi modelli sono spesso complessi e pesanti, rendendoli difficili da eseguire efficacemente su hardware edge come smartphone, dispositivi IoT, e altri apparati con limitazioni di memoria e potenza di calcolo.
L’ottimizzazione transformer edge è un insieme di tecniche progettate per ridurre le dimensioni e la complessità computazionale di questi modelli mantenendo un livello accettabile di precisione. L’importanza risiede nella capacità di rendere le potenti tecnologie AI accessibili in contesti in cui la capacità computazionale è limitata. Questo non solo espande le applicazioni pratiche dell’AI, ma permette anche di migliorare l’efficienza energetica, ciò che è fondamentale per l’uso sostenibile delle tecnologie in ambito globale.
Come funziona
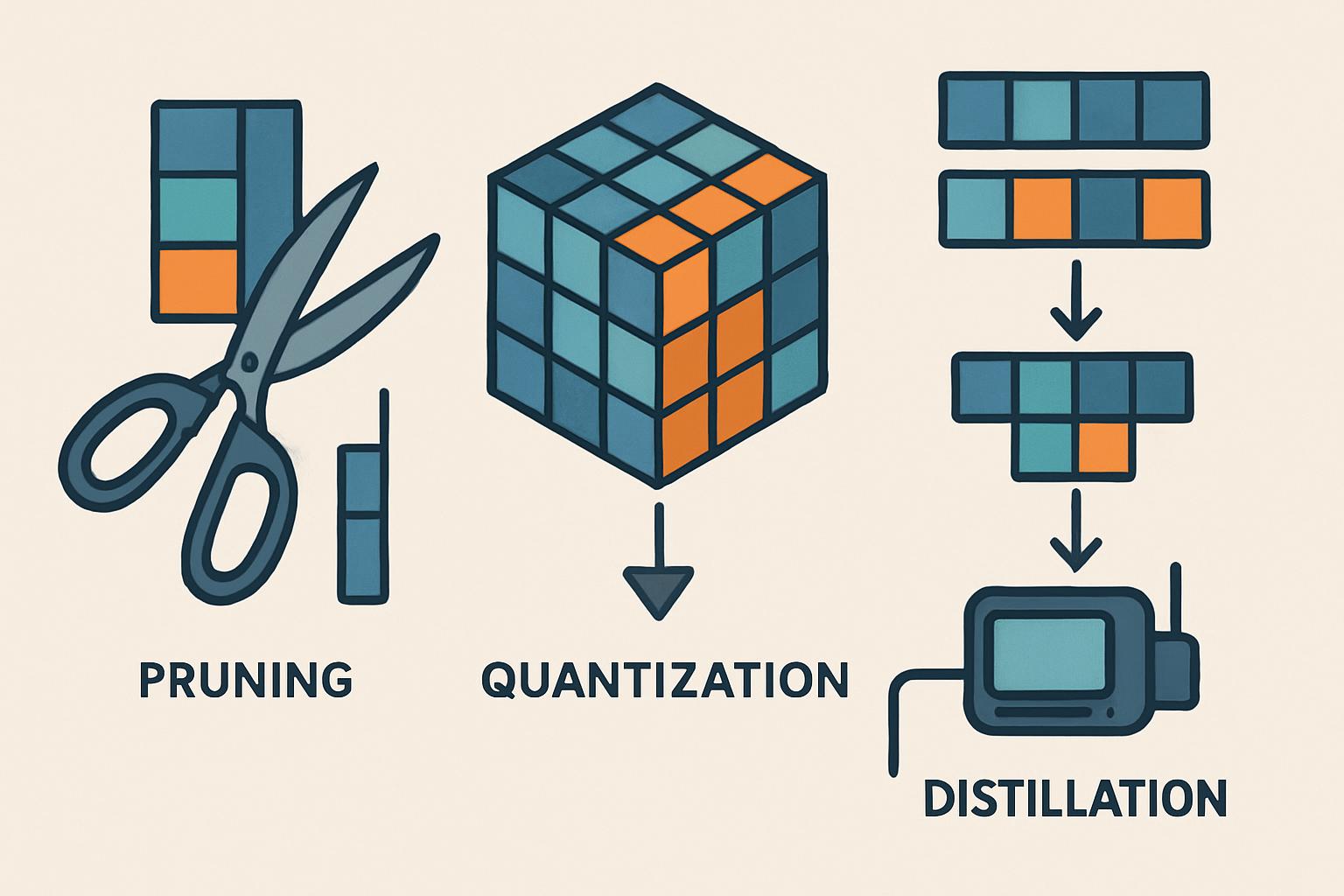
L’ottimizzazione dei modelli transformer per l’utilizzo su hardware edge coinvolge tre tecniche principali: pruning, quantizzazione e distillazione. Approfondiamo ciascuna di esse per comprendere i meccanismi alla base.
Pruning dei modelli AI
Il pruning è un processo che mira a rimuovere i neuroni inutili da una rete neurale, creando così una struttura più snella senza sacrificare significativamente la precisione del modello. Si basa sull’osservazione che molti pesi in una rete neurale profonda hanno un impatto trascurabile sulle decisioni complessive del modello.
- Identificazione: Si identificano i pesi che contribuiscono meno alla prestazione complessiva del modello.
- Eliminazione: Questi pesi vengono impostati su zero, semplificando il modello.
- Riaddestramento: Il modello viene quindi riaddestrato per recuperare la precisione persa a causa della rimozione di determinati pesi.
Il risultato è un modello più piccolo e più veloce, riducendo così i requisiti di elaborazione senza una significativa perdita di precisione.
Quantizzazione Transformer
La quantizzazione è un altro approccio per ridurre le dimensioni del modello e migliorare la velocità di elaborazione. Converte i numeri a 32 bit, comunemente utilizzati nei modelli AI, in numeri a minore precisione, come 16 o addirittura 8 bit.
- Codifica ridotta: Si tratta di ri-codificare i pesi e le attivazioni del modello in un formato di precisione inferiore.
- Elaborazione più veloce: La riduzione della precisione porta a un’elaborazione più rapida e a una minore richiesta di memoria.
Questo processo permette ai modelli di eseguire più velocemente e utilizzare meno risorse computazionali, cruciali per il deployment su hardware con capacità limitate.
Distillazione dei modelli
La distillazione dei modelli è una tecnica che trasferisce le conoscenze da un modello “insegnante” più grande a un modello “studente” più piccolo e più leggero. Questo metodo permette al modello studente di acquisire le capacità predittive dell’insegnante in una forma più compatta.
- Addestramento parallelo: Il modello insegnante e studente vengono addestrati in parallelo, con il modello studente che impara sulla base delle decisioni del modello insegnante.
- Conservazione della qualità: Sebbene il modello studente sia più piccolo, esso mantiene una qualità alta grazie alle informazioni apprese dal modello insegnante.
Questa tecnica è particolarmente efficace nel mantenere prestazioni elevate in modelli compressi, permettendone un utilizzo sulle piattaforme edge più limitate.
Applicazioni pratiche e casi d’uso
Le tecniche di ottimizzazione transformer edge trovano applicazione in una varietà di campi e scenari reali. Vediamo alcuni esempi pertinenti.
Assistenti Vocali Mobili
Gli assistenti vocali su smartphone, come Siri, Alexa, e Google Assistant, beneficiano enormemente da modelli AI ottimizzati per hardware edge. Grazie al pruning e alla quantizzazione, questi assistenti sono in grado di elaborare i comandi vocali con maggiore efficienza energetica, migliorando la reattività e riducendo il consumo della batteria.
Dispositivi IoT
Nel contesto della domotica e dei sensori intelligenti, la capacità di eseguire modelli AI direttamente sui dispositivi edge è cruciale. I processi di distillazione consentono di avere modelli leggeri capaci di eseguire inferenze localmente, riducendo la necessità di inviare continuamente dati a server esterni per l’elaborazione, migliorando così la latenza e la privacy.
Veicoli Autonomi
I veicoli autonomi richiedono l’elaborazione in tempo reale dei dati dei sensori. Dato che la capacità di calcolo a bordo è limitata, l’ottimizzazione dei modelli transformer consente ai veicoli di prendere decisioni rapide e precise, critiche per la sicurezza.
Vantaggi e sfide
L’ottimizzazione transformer edge offre numerosi vantaggi, ma presenta anche sfide significative che devono essere affrontate.
Vantaggi
Efficienza
L’ottimizzazione consente l’esecuzione di modelli complessi anche su dispositivi con limitata potenza computazionale, migliorando l’efficienza energetica e permettendo operazioni continue senza un grave impatto sulla durata della batteria.
Privacy
Eseguendo inferenze direttamente sul dispositivo, riduce la necessità di trasmettere dati privati a server remoti, aumentando la sicurezza dei dati personali e sensibilizzando sulla protezione della privacy.
Sfide
Accuratezza
Uno dei principali problemi è mantenere un alto livello di accuratezza nonostante la semplificazione del modello. Tecniche come la distillazione aiutano, ma ci sono trade-off inevitabili tra complessità del modello e precisione.
Cambiamenti Tecnologici
L’ottimizzazione richiede una profonda comprensione dei modelli e l’accesso a risorse computazionali per il riaddestramento, rappresentando quindi una barriera tecnologica per molte entità con risorse limitate.
Strumenti e tecnologie collegate
L’ottimizzazione per dispositivi edge è supportata da diverse librerie e framework, vediamone alcuni tra i più noti.
TensorFlow Lite
TensorFlow Lite è una versione leggera di TensorFlow progettata per l’uso su dispositivi mobili e integrati. Offre strumenti per la quantizzazione e il pruning efficienti, semplificando il deployment di modelli su piattaforme edge.
PyTorch Mobile
PyTorch Mobile permette l’esecuzione di modelli PyTorch su dispositivi mobile. Grazie a questo framework, gli sviluppatori possono facilmente quantizzare e ottimizzare i propri modelli per funzionare efficacemente sui dispositivi edge.
ONNX (Open Neural Network Exchange)
ONNX consente agli sviluppatori di convertire e ottimizzare modelli creati in framework diversi per una maggiore portabilità su diverse piattaforme, rendendolo ideale per sviluppare soluzioni nel campo dell’AI edge.
FAQ
Come posso iniziare a ottimizzare un modello transformer per hardware edge?
Inizia analizzando le possibilità offerte da strumenti come TensorFlow Lite e PyTorch Mobile. Identifica le sezioni del tuo modello che possono essere semplificate attraverso il pruning e considera l’uso della quantizzazione per ridurre la dimensione del modello.
La distillazione modello riduce sempre la precisione del modello?
Non necessariamente. La distillazione è progettata per trasferire efficacemente le informazioni critiche da un modello grande a uno piccolo. Tuttavia, esiste ancora un equilibrio. In pratica, con una corretta applicazione, le perdite di precisione possono essere minime.
È necessario avere esperienza approfondita per ottimizzare i modelli per l’edge?
Un certo livello di comprensione delle reti neurali e delle tecniche di ottimizzazione è certamente utile, ma molte piattaforme e strumenti oggi offrono metodologie plug-and-play che riducono la necessità di una profonda conoscenza tecnica.
Conclusione
L’ottimizzazione transformer edge non è solo un elemento migliorativo per le applicazioni AI moderne, ma una necessità crescente. Mentre il mondo continua a evolversi verso un ecosistema connesso e intelligente, la capacità di eseguire modelli complessi su hardware limitati diventerà sempre più critica. Conoscere e applicare tecniche come il pruning, la quantizzazione e la distillazione consente di massimizzare l’efficienza e aprire nuovi orizzonti per l’AI su dispositivi edge. Per chi desidera restare all’avanguardia nel mondo dell’AI, il cammino verso l’ottimizzazione non finisce qui e vi invitiamo a esplorare ulteriormente attraverso i numerosi approfondimenti disponibili sul nostro blog.
Potrebbe interessarti anche...

Progettare sistemi di riconoscimento vocale per lingue minoritarie
Progettare Sistemi di Riconoscimento Vocale per le Lingue Minoritarie: Sfide e Opportunità
Leggi
Gestire bias e fairness nei dataset per modelli di intelligenza artificiale
Gestire Bias e Fairness nei Dataset per Modelli di Intelligenza Artificiale: Strategie e Strumenti
Leggi
Automatizzare la classificazione di immagini satellitari con deep learning
Automatizzare la classificazione delle immagini satellitari con il deep learning: una guida pratica
Leggi🤖 L’AI sta rivoluzionando il business. Se non la usi tu, lo farà la concorrenza.
Prenota una call gratuita